I have been trying to debug a bug that was causing the records being returned out of the date window. It took me some time to realize that ADO.Net was rounding the C# DateTime and that was causing the invalid records to be returned.
My table looks somewhat like this:
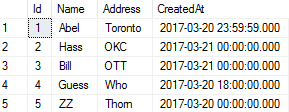
and the code was:
using (SqlConnection conn = new SqlConnection("server=localhost\\SQLExpress;Database=TestDB;Trusted_Connection=True"))
using (SqlCommand cmd = new SqlCommand("SELECT * FROM MyTestTable WHERE CreatedAt <= @dateTimeParameter", conn))
{
if(conn.State != ConnectionState.Open) conn.Open();
DateTime dtParameter = new DateTime(2017,03,20);
dtParameter = dtParameter.AddDays(1).AddTicks(-1); //The last moment on particular date
cmd.Parameters.Add(new SqlParameter("@dateTimeParameter", SqlDbType.DateTime) {Value = dtParameter});
DataTable dt = new DataTable();
dt.Load(cmd.ExecuteReader());
}
With this code in place, I was trying to get the records for the last moment on March 20th. I ended up using the following code to get the last moment on the particular date.
DateTime dtParameter = new DateTime(2017,03,20); dtParameter = dtParameter.AddDays(1).AddTicks(-1);
But when this code was executed, I got the records for the next day as well, which was clearly not intended. I tried SqlDateTime type as parameter, but it still had the same effect.
var sqlDateTime = new SqlDateTime(dtParameter);
cmd.Parameters.Add(new SqlParameter("@dateTimeParameter", SqlDbType.DateTime) { Value = sqlDateTime });
One thing I noticed using SqlDateTime is that the Ticks rounded to 636256512000000000 from 636256511999999999, during the conversion.
This forced me to look at the reference code for SqlDateTime, the constructor called method to get SqlDateTime from DateTime, at the end of method chain, I found the method with the following comment
// Convert from TimeSpan, rounded to one three-hundredth second, due to loss of precision
private static SqlDateTime FromTimeSpan(TimeSpan value) {
This was the reason the DateTime was getting rounded to the next day. The fix was to use Milliseconds to get the last moment of the day. Even passing a single millisecond wasn’t enough , I had to use 2.
dtParameter = dtParameter.AddDays(1).AddMilliseconds(-2);
This fixed the issue and I was able to get the records for the date window.